Improve code generation for Cmm switches by "floating out" the value expression.
Summary
Cmm switches are often compiled to a binary search over the cases.
#define ENTER_(ret,x) \
again: \
W_ info; \
LOAD_INFO(ret,x) \
/* See Note [Heap memory barriers] in SMP.h */ \
prim_read_barrier; \
switch [INVALID_OBJECT .. N_CLOSURE_TYPES] \
(TO_W_( %INFO_TYPE(%STD_INFO(info)) )) { \
case \
IND, \
IND_STATIC: \
{ \
x = StgInd_indirectee(x); \
goto again; \
} \
case \
FUN, \
FUN_1_0, \
FUN_0_1, \
FUN_2_0, \
FUN_1_1, \
FUN_0_2, \
FUN_STATIC, \
BCO, \
PAP: \
{ \
ret(x); \
} \
default: \
{ \
x = UNTAG_IF_PROF(x); \
jump %ENTRY_CODE(info) (x); \
} \
}The control flow will look something like this:
So far so good.
The problem however is that the expression based on which we switch seems to get inlined and as such will get recomputed at every branch.
For example this is the switch expression of the ENTER macro once parsed by GHC:
switch [0 .. 64] (%MO_SS_Conv_W32_W64(I32[_c3::I64 - 8])) {
case 8, 9, 10, 11, 12, 13, 14, 23, 25 : goto c9;
case 27, 28 : goto c8;
default: {goto c7;}
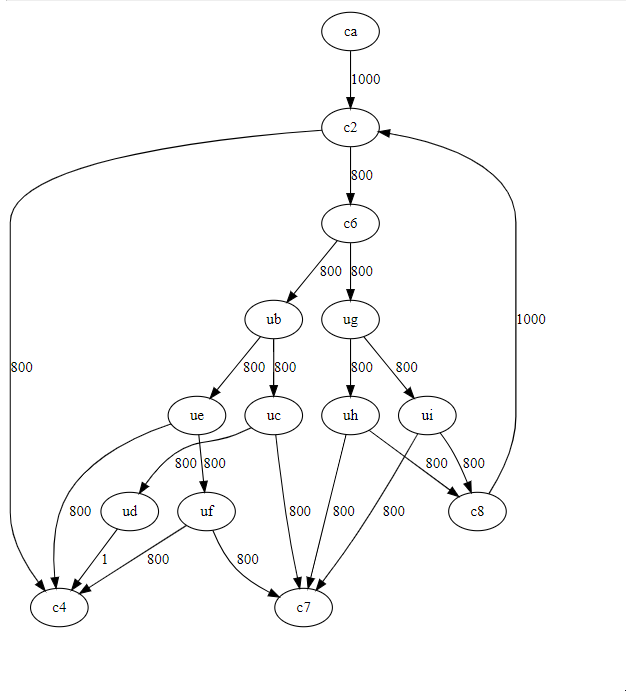
} // CmmSwitchOnce GHC is done optimizing this it comes out as this:
==================== Optimised Cmm ====================
stg_ap_0_fast() { // [R1]
{ []
}
{offset
ca: // global
//tick src<Apply.cmm:(25,1)-(192,1)>
_c1::P64 = R1; // CmmAssign
goto c2; // CmmBranch
c2: // global
if (_c1::P64 & 7 != 0) goto c4; else goto c6; // CmmCondBranch
c6: // global
//tick src<Apply.cmm:35:80-96>
_c3::I64 = I64[_c1::P64]; // CmmAssign
if (I32[_c3::I64 - 8] < 26 :: W32) goto ub; else goto ug; // CmmCondBranch
ub: // global
if (I32[_c3::I64 - 8] < 15 :: W32) goto uc; else goto ue; // CmmCondBranch
uc: // global
if (I32[_c3::I64 - 8] < 8 :: W32) goto c7; else goto ud; // CmmCondBranch
ud: // global
switch [8 .. 14] (%MO_SS_Conv_W32_W64(I32[_c3::I64 - 8])) {
case 8, 9, 10, 11, 12, 13, 14 : goto c4;
} // CmmSwitch
ue: // global
if (I32[_c3::I64 - 8] >= 25 :: W32) goto c4; else goto uf; // CmmCondBranch
uf: // global
if (%MO_SS_Conv_W32_W64(I32[_c3::I64 - 8]) != 23) goto c7; else goto c4; // CmmCondBranch
c4: // global
//tick src<Apply.cmm:35:261-276>
//tick src<Apply.cmm:35:58-73>
R1 = _c1::P64; // CmmAssign
call (P64[Sp])(R1) args: 8, res: 0, upd: 8; // CmmCall
ug: // global
if (I32[_c3::I64 - 8] < 28 :: W32) goto uh; else goto ui; // CmmCondBranch
uh: // global
if (I32[_c3::I64 - 8] < 27 :: W32) goto c7; else goto c8; // CmmCondBranch
ui: // global
if (I32[_c3::I64 - 8] < 29 :: W32) goto c8; else goto c7; // CmmCondBranch
c8: // global
//tick src<Apply.cmm:35:169-220>
//tick src<Apply.cmm:35:175-206>
_c1::P64 = P64[_c1::P64 + 8]; // CmmAssign
goto c2; // CmmBranch
c7: // global
//tick src<Apply.cmm:35:287-332>
//tick src<Apply.cmm:35:293-300>
R1 = _c1::P64; // CmmAssign
call (_c3::I64)(R1) args: 8, res: 0, upd: 8; // CmmCall
}
}We have duplicated the expression I32[_c3::I64 - 8] 9 times! MO_SS_Conv_W32_W64 only get's eliminated from the expression because it is a noop at this stage.
This expression isn't all that complicated, so it's not a huge issue. But still if we need 4 comparisons to reach a leaf node it means we will read from memory four times instead of just branching on a register value.
Instead when compiling switch expressions we should lift out the expression we switch on, assign it to an variable and then branch on this variable.
This shouldn't effect compiled Haskell code much, as this pattern seems to occur rarely there. But it should help handwritten Cmm and by extension RTS performance a bit.
Environment
GHC-Head, x86